
ARRK Engineering has carried out a number of tests using deep learning and CNN models to identify driver distraction as a result of activities such as eating, drinking and making phone calls. Here’s what the company found out
According to a report by the World Health Organization (WHO), each year about 1.35 million people die in traffic accidents and another 20 to 50 million are injured. One of the main causes is driver inattention.
For years, the automotive industry has installed systems that warn in case of driver fatigue. These driver assistants analyze, for example, the viewing direction of the driver, and automatically detect deviations from normal driving behavior. “Existing warning systems can only correctly identify specific hazard situations,” reports Benjamin Wagner, senior consultant for Driver Assistance Systems at ARRK Engineering. “But during some activities like eating, drinking and phoning, the driver’s viewing direction remains aligned with the road ahead.”
For that reason, ARRK Engineering ran a series of tests to identify a range of driver postures so systems can automatically detect the use of mobile phones and eating or drinking. For the system to correctly identify all types of visual, manual and cognitive distraction, ARRK tested various CNN models with deep learning and trained them with the collected data.
Creation of the first image dataset for teaching the systems
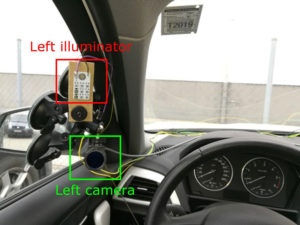 In the test setup, two cameras with active infrared lighting were positioned to the left and right of the driver on the A-column of a test vehicle. Both cameras had a frequency of 30 Hz and delivered 8-bit grayscale images at 1280 x 1024 pixel resolution.
In the test setup, two cameras with active infrared lighting were positioned to the left and right of the driver on the A-column of a test vehicle. Both cameras had a frequency of 30 Hz and delivered 8-bit grayscale images at 1280 x 1024 pixel resolution.
“The cameras were also equipped with an IR long-pass filter to block out most of the visual spectrum light at wavelengths under 780nm,” explains Wagner. “In this manner we made sure that the captured light came primarily from the IR LEDs and that their full functionality was assured during day and night time.”
In addition, blocking visible daylight prevented shadow effects in the driver area that might otherwise have led to mistakes in facial recognition. A Raspberry Pi 3 Model B+ sent a trigger signal to both cameras to synchronize the moment of image capture.
With this setup, images were captured of the postures of 16 test persons in a stationary vehicle. To generate a wide range of data, the test persons differed in gender, age, and headgear, as well as using different mobile phone models and consuming different foods and beverages.
“We set up five distraction categories that driver postures could later be assigned to. These were: ‘no visible distraction,’ ‘talking on smartphone,’ ‘manual smartphone use,’ ‘eating or drinking’ and ‘holding food or beverage,’” explains Wagner. “For the tests, we instructed the test persons to switch between these activities during simulated driving.”
After capture, the images from the two cameras were categorized and used for model training.
Training and testing the image classification systems
Four modified CNN models were used to classify driver postures: ResNeXt-34, ResNeXt-50, VGG-16 and VGG-19. The last two models are widely used in practice, while ResNeXt-34 and ResNeXt-50 contain a dedicated structure for processing of parallel paths.
To train the system, ARRK ran 50 epochs using the Adam optimizer, an adaptive learning rate optimization algorithm. In each epoch, the CNN model had to assign the test persons’ postures to the defined categories. With each step, this categorization was adjusted by a gradient descent method, so that the fault rate could be lowered continuously.
After model training, a dedicated test dataset was used to calculate the error matrix which allowed an analysis of the fault rate per driver posture for each CNN model.
“The use of two cameras, each with a separately trained CNN model, enables ideal case differentiation for the left and right side of the face,” explains Wagner. “Thanks to this process, we were able to identify the system with the best performance in recognizing the use of mobile phones and consumption of food and beverages.”
Evaluation of the results showed that the ResNeXt-34 and ResNeXt-50 models achieved the highest classification accuracy, 92.88 percent for the left camera and 90.36% for the right camera. This is absolutely competitive with existing solutions for detection of driver fatigue.
Using this information, ARRK has extended its training database which now contains around 20,000 labeled eye data records. Based on this, it is possible to develop an automated vision-based system to validate driver monitoring systems.
ARRK Engineering’s experts are already planning another step to further reduce the fault rate. “To further improve accuracy, we will use other CNN models in a next project,” notes Wagner. “Besides evaluation of different classification models, we will analyze whether the integration of associated object positions from the camera image can achieve further improvements.”
In this context, approaches will be considered that are based on bounding box detection and semantic segmentation. The latter enable, in addition to classification, different levels of detail regarding the localization of objects. In this way, ARRK can improve the accuracy of driver assistance systems for the automatic detection of driver distraction.